U posljednjem desetljeću, napredak u području umjetne inteligencije i strojnog učenja donio je značajne promjene u mnogim industrijama, uključujući i tehnologiju obrade prirodnog jezika (NLP). Jedan od najistaknutijih primjera takvog napretka je BERT (Bidirectional Encoder Representations from Transformers), model koji je transformirao način na koji računala razumiju ljudski jezik. U ovom blogu istražit ćemo kako se BERT može koristiti za klasifikacijske zadatke, posebno u kontekstu analize teksta.
BERT (Bidirectional Encoder Representations from Transformers) je model koji koristi tehnike strojnog učenja i umjetne inteligencije za obradu prirodnog jezika (NLP). Razvijen od strane istraživača u Googleu 2018. godine, BERT je brzo postao jedan od najvažnijih alata u NLP-u zbog svoje svestranosti i efikasnosti. Ovaj model koristi inovativnu arhitekturu zvanu “transformatori” za bolje razumijevanje konteksta unutar teksta. Evo detaljnijeg objašnjenja kako BERT funkcioniše i zašto je tako revolucionaran.
BERT je zasnovan na konceptu transformera, posebice na njihovom enkoderskom dijelu. Transformeri su modeli koji koriste mehanizme pozornosti da bi efikasno obradili podatke koji ulaze u model. Ključna inovacija BERT-a je njegova sposobnost da obradi rečenice u oba smjera (bidirekcionalno) istovremeno, za razliku od prethodnih modela koji su tekst obrađivali linearno, od početka prema kraju ili obrnuto. Mehanizam pozornosti omogućava modelu da fokusira i “razumije” važne dijelove teksta više nego manje relevantne dijelove. To pomaže BERT-u da kontekstualno analizira upotrebu riječi u rečenici, što rezultira boljim razumijevanjem značenja teksta.
Jedna od najmoćnijih karakteristika BERT-a je njegova sposobnost predobuke na velikom korpusu tekstova i prilagodbe (fine-tuning) za specifične zadatke.
Klasifikacija Teksta s BERT-om
Klasifikacija teksta jedan je od najčešćih primjena BERT modela. Ovaj proces uključuje analizu i kategorizaciju tekstualnih podataka u predefinirane kategorije. Evo nekoliko koraka kako BERT može biti implementiran za klasifikaciju:
Predobrada Teksta: Prije nego što se tekst može obraditi pomoću BERT-a, mora se pripremiti. To uključuje tokenizaciju teksta, gdje se rečenice razbijaju na riječi ili fraze, te konverziju tih tokena u format koji BERT može obraditi.
Fine-tuning Modela: Iako BERT dolazi prethodno obučen na općem skupu podataka, za specifične zadatke klasifikacije često je potrebno dodatno prilagoditi model. Ovaj proces, poznat kao fine-tuning, uključuje treniranje modela na skupu podataka specifičnim za određeni zadatak kako bi se optimizirala njegova točnost.
Evaluacija Modela: Nakon fine-tuninga, model se testira na nevidljivom skupu podataka kako bi se procijenila njegova učinkovitost. Metrike kao što su točnost, preciznost, i F1 ocjena koriste se za mjerenje uspješnosti modela u klasifikaciji teksta.

REZULTATI
| Epoch | Training | Validation | ||
|---|---|---|---|---|
| Average Loss | Average Accuracy | Average Loss | Accuracy | |
| 1 | 0.1635 | 92.99% | 0.0966 | 95.50% |
| 2 | 0.0979 | 96.00% | 0.1075 | 95.60% |
| 3 | 0.0626 | 97.60% | 0.0937 | 95.90% |
| 4 | 0.0426 | 98.39% | 0.1509 | 95.20% |
| 5 | 0.0325 | 98.83% | 0.1224 | 95.90% |
| 6 | 0.0211 | 99.27% | 0.1732 | 95.50% |
| 7 | 0.0173 | 99.38% | 0.1541 | 96.70% |
| 8 | 0.0136 | 99.61% | 0.1120 | 96.60% |
| 9 | 0.0098 | 99.71% | 0.1577 | 96.20% |
| 10 | 0.0107 | 99.68% | 0.1304 | 96.40% |
Točnost Validacije (Validation Accuracy)
- Točnost Validacije: 0.9640 – Ova metrika pokazuje udio točno klasificiranih instanci u odnosu na ukupan broj instanci u validacijskom skupu. Vrijednost od 0.9640 znači da je model točno klasificirao 96.40% slučajeva, što ukazuje na visoku razinu točnosti i pokazuje da model vrlo dobro generalizira na nove podatke koji nisu korišteni tijekom treninga.
Preciznost (Precision)
- Preciznost: 0.9648 – Preciznost mjeri udio ispravno pozitivnih predikcija u odnosu na ukupan broj pozitivnih predikcija koje je model izvršio. Vrijednost od 0.9648 sugerira da kada model predvidi pozitivan ishod, postoji 96.48% šanse da je to predviđanje točno. Ovo je osobito važno u aplikacijama gdje su posljedice lažno pozitivnih rezultata ozbiljne.
Odziv (Recall)
- Odziv: 0.9636 – Odziv mjeri udio ispravno pozitivnih predikcija u odnosu na ukupan broj stvarnih pozitivnih slučajeva u skupu podataka. Vrijednost od 0.9636 znači da model uspješno identificira 96.36% svih stvarnih pozitivnih slučajeva. Visok odziv je ključan u situacijama gdje je kritično ne propustiti pozitivne slučajeve, poput medicinske dijagnostike ili sigurnosnih aplikacija.
F1 Ocijena (F1 Score)
- F1 Ocijena: 0.9639 – F1 ocjena je harmonijski prosjek preciznosti i odziva, što ga čini pouzdanom metrikom za ocjenjivanje ukupne točnosti modela, posebno kada su klase neravnomjerno zastupljene. F1 ocjena od 0.9639 ukazuje na to da model vrlo dobro balansira između preciznosti i odziva, čineći ga pouzdanim u različitim operativnim uvjetima.
- ROC AUC Ocijena: 0.9636 – Vrijednost ROC AUC ocjene kreće se od 0 do 1, gdje ocjena 1 predstavlja savršenu sposobnost razlikovanja između pozitivnih i negativnih klasa, dok ocjena 0.5 ukazuje na potpunu nesposobnost modela da razlikuje klase (slično nasumičnom pogađanju). Ocjena od 0.9636 stoga ukazuje na vrlo visoku sposobnost modela da ispravno razlikuje pozitivne od negativnih slučajeva, što je posebno važno u aplikacijama gdje je važna precizna klasifikacija.
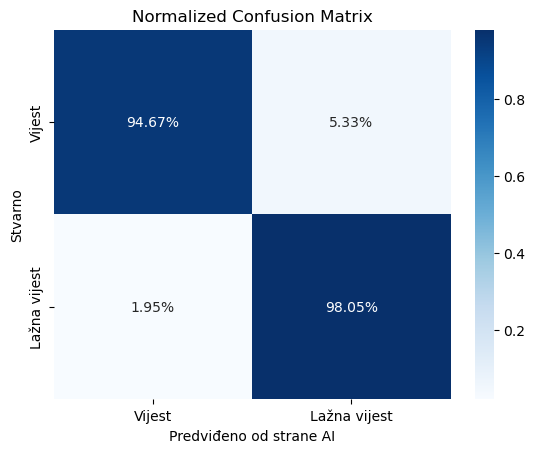
Normalizirana matrica zabune
Normalizirana matrica zabune koristan je alat za evaluaciju performansi klasifikacijskih modela, posebno kada se radi o binarnim klasifikacijama kao što su kategorije “Vijest” i “Lažna vijest”. Ova matrica pruža vizualni prikaz točnosti modela u predviđanju svake klase te omogućuje dublje razumijevanje kako model performira na stvarnim podacima u odnosu na predviđanja modela. U kontekstu naših podataka, normalizirana matrica zabune za dvije klase (“Vijest” i “Lažna vijest”) daje sljedeće vrijednosti:- Pravi pozitivi (True Positives) za Vijest: 94.67% – Ovo znači da je model točno klasificirao 94.67% stvarnih vijesti kao vijesti.
- Lažni pozitivi (False Positives) za Lažna Vijest: 5.33% – Ovo znači da je model pogrešno klasificirao 5.33% stvarnih vijesti kao lažne vijesti.
- Lažni negativi (False Negatives) za Vijest: 1.95% – Ovo pokazuje da je model pogrešno klasificirao 1.95% stvarnih lažnih vijesti kao vijesti.
- Pravi pozitivi (True Positives) za Lažna Vijest: 98.05% – Ovo znači da je model točno klasificirao 98.05% stvarnih lažnih vijesti kao lažne vijesti.
Analiza Rezultata
- Visoka Točnost za “Lažna Vijest”: Visoka vrijednost pravih pozitiva za lažne vijesti (98.05%) ukazuje na to da model vrlo učinkovito identificira lažne vijesti, što je ključno u kontekstima gdje je važno spriječiti širenje dezinformacija.
- Niža, ali još uvijek visoka Točnost za “Vijest”: Iako je točnost za prave vijesti nešto niža (94.67%), ona je i dalje prilično visoka, što pokazuje da model generalno dobro prepoznaje i vijesti koje su istinite.
- Razmjerno Niski Lažni Pozitivi i Negativi: Iako svaki lažni pozitiv ili negativ predstavlja potencijalni problem, relativno niske vrijednosti za lažne pozitive (5.33%) i lažne negativne (1.95%) pokazuju da model uspješno balansira između prepoznavanja istinitih i lažnih vijesti bez velike količine pogrešaka.