

BERTić je transformativni model temeljen na principu transformera, koji je prethodno treniran na 8 milijardi tokena izvađenih s web stranica na hrvatskom, bosanskom, srpskom i crnogorskom jeziku.
BERTić — The Transformer Language Model for Bosnian, Croatian, Montenegrin and Serbian. Nikola Ljubešić, Davor Lauc
Ovaj model se evaluira kroz različite zadatke, kao što su označavanje dijelova govora, prepoznavanje imenovanih entiteta, predviđanje geolokacije i razumijevanje uzročno-posljedičnih veza u općem znanju, pri čemu pokazuje poboljšanja u odnosu na najnovije modele za sve navedene zadatke. Za evaluaciju razumijevanja zdravorazumskih zaključivanja uveli smo COPA-HR, koji predstavlja prijevod testa Choice of Plausible. Za treniranje ovog modela odabran je pristup Electra (Clark et al., 2020), koji se temelji na treniranju manjeg generatora modela i većeg glavnog diskriminatornog modela čiji je zadatak razlikovati da li je određena riječ izvorna riječ iz teksta ili riječ generirana od strane generatora. Autori tvrde da je Electra pristup računalno učinkovitiji od modela BERT (Devlin et al., 2018) koji se temelji na maskiranom modeliranju jezika.
ELECTRA model je novi pristup treniranju jezičnih modela koji unapređuje efikasnost i efektivnost u odnosu na prethodne metode poput BERT-a. Umjesto da samo maskira i predviđa riječi, ELECTRA koristi generator za stvaranje zamjenskih riječi u tekstu koje zatim diskriminator pokušava identificirati, što rezultira bržim i ekonomičnijim učenjem. Ova metoda je pokazala izvanredne rezultate u mnogim jezičnim zadacima i omogućava izgradnju moćnijih modela s manje računalne snage.
Klasifikacija teksta uporabom BERTić ( ELEKTRA) modela
Klasifikacija teksta pomoću modela ELECTRA koristi jedinstveni pristup predobuci, koji se značajno razlikuje od drugih modela poput BERT-a. Metodologija obuke ELECTRA uključuje dva glavna komponenta: generator i diskriminator. Ova metoda, koju su predstavili Clark i suradnici 2020. godine, pokazala se računalno učinkovitom i učinkovitom, posebno za zadatke poput klasifikacije teksta.
ELECTRA predstavlja Efficiency Learning an Encoder that Classifies Token Replacements Accurately (Učinkovito učenje enkodera koji točno klasificira zamjene tokena). Za razliku od tradicionalnih modela koji uče predvidjeti maske tokene (kao što je BERT), ELECTRA uči razlikovati “stvarne” i “lažne” tokene kroz cijelu ulaznu sekvencu. Ovaj pristup je u osnovi problem binarne klasifikacije na razini tokena, koji trenira model da razumije i obrađuje jezik učinkovitije.je.
Obuka Modela ELECTRA
Generator: Generator je manji transformer model koji uči predvidjeti vjerojatne tokene za zamjenu u ulaznom tekstu. To je slično zadatku modela maske jezika u BERT-u, ali uključuje zamjenu tokena umjesto predviđanja maskiranih tokena.
Diskriminator: Glavni model, diskriminator, uči razlikovati je li svaki token u ulaznoj sekvenci “stvarni” token iz skupa podataka ili “lažni” token proizveden od strane generatora. Diskriminator je fino podešen za ovaj zadatak, koji tijesno nalikuje krajnjim zadacima (kao što je klasifikacija teksta) koje će izvoditi.
Klasifikacija Teksta s ELECTRA
Predobuka: Tijekom predobuke, generator i diskriminator se istovremeno obučavaju. Generator zamjenjuje neke tokene u tekstu alternativama koje predviđa, dok diskriminator pokušava identificirati je li svaki token u tekstu izvorni ili zamijenjen. To uči diskriminator fino razumijevanje jezika.
Fino podešavanje: Jednom predobučen, model diskriminatora zatim se fino podešava za specifične zadatke nizvodno kao što su klasifikacija teksta. Fino podešavanje uključuje obuku diskriminatora na označenom skupu podataka gdje su ulazi tekstualni dokumenti, a izlazi su kategorije ili oznake.
Sloj za Klasifikaciju: Da bi se prilagodio diskriminator za klasifikaciju, dodaje se sloj za klasifikaciju na vrh izlaza transformatora. Ovaj sloj mapira izlazne ugradnje teksta na potencijalne kategorije.
REZULTATI:
Model BERTić bio je obučen na WELFake skupu podataka koji je prethodno preveden na hrvatski jezik. Korištenjem ovog lokaliziranog skupa podataka, model je uspio naučiti specifičnosti hrvatskog jezičnog izraza. Ova prilagodba omogućila je precizniju analizu i klasifikaciju tekstova na hrvatskom jeziku. Kada se obučava model poput BERTića na specifičnom skupu podataka, važno je pratiti ključne metrike tijekom procesa obuke kako bi se ocijenila učinkovitost i prilagodba modela. U slučaju obuke na WELFake skupu podataka koji je preveden na hrvatski, važne metrike su uključivale prosječni gubitak i točnost kroz različite epohe, kako za treniranje tako i za validaciju.
Analiza podataka o obuci modela BERTić za klasifikaciju teksta pruža uvid u učinkovitost i prilagodljivost modela kroz deset epoha obuke. Evo detaljnog pregleda rezultata dobivenih tijekom treninga i validacije: Pregled Podataka Tijekom prvih nekoliko epoha, vidljivo je značajno poboljšanje kako u točnosti tako i u smanjenju gubitka na trening setu. Slično, točnost na validacijskom setu pokazuje dobre rezultate, što ukazuje na to da model dobro generalizira na novim podacima. BERTić model pokazuje izvrsne performanse na trening setu s vrlo visokom točnošću i niskim gubitkom, što ukazuje na uspješnu obuku. Iako postoji određena fluktuacija u točnosti validacije, model generalno dobro prenosi naučeno na validacijski set. Međutim, potrebno je obratiti pozornost na mogući overfitting, posebno u kasnijim epohama. Analiziramo rezultate validacije modela BERTić koji su pokazali izvanrednu usklađenost u svim ključnim metrikama ocjenjivanja performansi modela. Sve ključne metrike — točnost validacije, preciznost, odziv, F1 skor i ROC AUC skor — iznose 0.9715. Ovdje je detaljna analiza tih rezultata i što oni značaju za model BERTić:
| Epoch | Training Average Loss | Training Average Accuracy | Validation Average Loss | Validation Accuracy |
|---|---|---|---|---|
| 1 | 0.2456 | 89.52% | 0.1138 | 95.30% |
| 2 | 0.0842 | 96.88% | 0.0699 | 97.15% |
| 3 | 0.0481 | 98.19% | 0.1124 | 96.10% |
| 4 | 0.0284 | 99.04% | 0.0838 | 97.15% |
| 5 | 0.0144 | 99.45% | 0.1107 | 97.00% |
| 6 | 0.0125 | 99.52% | 0.1420 | 96.75% |
| 7 | 0.0087 | 99.69% | 0.1590 | 96.20% |
| 8 | 0.0131 | 99.58% | 0.1050 | 97.25% |
| 9 | 0.0069 | 99.79% | 0.1716 | 96.25% |
| 10 | 0.0062 | 99.74% | 0.1276 | 97.15% |
Opća Analiza Rezultata
Sve metrike postigle su identičnu vrijednost od 0.9715, što sugerira vrlo uravnotežene performanse modela u različitim aspektima evaluacije: Točnost Validacije (Accuracy): Ova metrika pokazuje koliki je udio ukupnih predikcija modela točan. Visoka točnost ukazuje na to da model dobro razlikuje ciljne klase u većini slučajeva. Preciznost (Precision): Preciznost mjeri udio točnih pozitivnih predikcija u odnosu na ukupan broj pozitivnih predikcija koje je model izvršio. Visoka preciznost implicira nisku stopu lažno pozitivnih rezultata, što je posebno važno u aplikacijama gdje su posljedice lažnih alarma visoke. Odziv (Recall): Odziv, ili stopa istinito pozitivnih, pokazuje koliko je dobro model identificirao sve stvarne pozitivne slučajeve. Visok odziv znači da model uspješno prepoznaje većinu pozitivnih primjera. F1 Skor: F1 skor je harmonijska sredina preciznosti i odziva. Visoki F1 skor ukazuje na to da model efikasno balansira između preciznosti i odziva, što je ključno u situacijama gdje je potrebno optimalno izbalansirati oba aspekta. ROC AUC Skor: ROC AUC mjera je sposobnost modela da diskriminira između klasa nezavisno o pragu klasifikacije. Skor od 0.9715 ukazuje na izvrsnu diskriminativnu sposobnost modela. Visoka ujednačenost u svim mjerama performansi sugerira da model BERTić ne samo da točno predviđa kategorije, nego to čini s minimalnom pristranošću prema lažno pozitivnim ili lažno negativnim rezultatima. To je osobito važno za aplikacije koje zahtijevaju visoku pouzdanost u predikcijama, kao što su obrada prirodnog jezika i analiza sentimenta u pravnim i financijskim dokumentima.
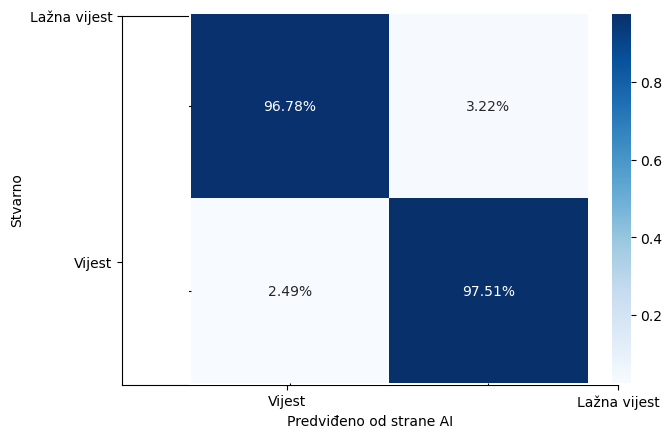
Normalizirana matrica zabune
Normalizirana matrica zabune ključan je alat za analizu performansi klasifikacijskih modela, omogućujući detaljno razumijevanje kako model predviđa različite klase. U kontekstu klasifikacije s dvije klase, “Vijest” i “Lažna vijest”, normalizirana matrica zabune pruža uvid u to kako model razlikuje te dvije klase. Evo analize rezultata koji su dani: 96.78%, 3.22%, 2.49% i 97.51%.
Struktura Matrice Zabune
Pravi pozitivi (Vijest): 96.78% – Ovaj postotak predstavlja udio stvarnih vijesti koje su točno klasificirane kao vijesti. Visoka vrijednost ukazuje na to da model vrlo učinkovito prepoznaje stvarne vijesti.
Lažni pozitivi (Lažna vijest): 3.22% – Ovo predstavlja situacije gdje su stvarne vijesti pogrešno klasificirane kao lažne vijesti. Iako je postotak relativno nizak, svaki slučaj lažno pozitivne klasifikacije može potencijalno širiti dezinformacije.
Lažni negativi (Vijest): 2.49% – Ovo su slučajevi kada su lažne vijesti pogrešno identificirane kao stvarne vijesti. Slično lažnim pozitivima, i ovi rezultati mogu imati negativne posljedice, posebno u kontekstima gdje je važna točna informacija.
Pravi pozitivi (Lažna vijest): 97.51% – Ovaj visoki postotak pokazuje da model efikasno identificira lažne vijesti kao lažne. Ovo je ključno u borbi protiv dezinformacija, gdje je važno precizno filtrirati i eliminirati neistinite sadržaje.
Značaj i Implikacije Rezultata
Visoki postotci pravih pozitiva za obje klase (96.78% za vijesti i 97.51% za lažne vijesti) ukazuju na to da model generalno dobro funkcioniše u identifikaciji i klasifikaciji sadržaja. Međutim, iako su relativno niski, postotci lažnih pozitiva i negativa zaslužuju pažnju zbog potencijalnih rizika i posljedica koje mogu proizaći iz pogrešnih klasifikacija.
Rezultati validacije modela BERTić pokazuju da je model iznimno robustan i pouzdan u klasifikaciji teksta. Visoka ujednačenost u metrikama točnosti, preciznosti, odziva, F1 skora i ROC AUC skora ukazuje na to da model može biti vrlo koristan u stvarnim primjenama gdje je potrebna visoka točnost i pouzdanost