

Optimalno Rješenje za Klasifikaciju i Detekciju Lažnih Vijesti
U svijetu obrade prirodnog jezika (NLP), DistilBERT se ističe ne samo svojom efikasnošću nego i specifičnim primjenama koje optimalno koriste njegove sposobnosti. Jedna od najčešćih upotreba DistilBERT-a je u zadacima klasifikacije, gdje model demonstrira izvanredne sposobnosti u različitim domenama.
DistilBERT je pojednostavljena verzija modela BERT (Bidirectional Encoder Representations from Transformers), dizajnirana da bude manja, brža, jeftinija i lakša. Kroz proces destilacije znanja, DistilBERT uspijeva zadržati preko 95% performansi originalnog BERT modela, dok koristi 40% manje parametara i radi 60% brže. Takva efikasnost ga čini idealnim za primjene gdje su resursi skromni.
U svojoj osnovi, DistilBERT koristi tehniku poznatu kao destilacija znanja tijekom faze prethodnog treniranja. Ovaj pristup omogućava modelu da naslijedi “induktivne pristranosti” koje su veći modeli stekli tijekom prethodnog treniranja. Konkretno, DistilBERT uvodi trostruki gubitak koji kombinira modeliranje jezika, destilaciju znanja i gubitke udaljenosti kosinusa, čime se postižu visoke performanse smanjenog modela.
DistilBERT i Klasifikacija
DistilBERT je, zbog svoje arhitekture i sposobnosti učenja, idealan za klasifikacijske zadatke u NLP-u. Ovaj model može efikasno obraditi i kategorizirati tekstualne podatke, što ga čini savršenim alatom za različite aplikacije, od sentiment analize do kategorizacije sadržaja. Zbog smanjenog broja parametara u odnosu na originalni BERT model, DistilBERT zahtijeva manje računalnih resursa, omogućavajući brže obrade podataka uz održavanje visoke točnosti. Ovo je ključno za primjene gdje brzina i efikasnost obrade velikih količina podataka igraju vitalnu ulogu.
DistilBERT u Borbi protiv Lažnih Vijesti
Posebno značajno područje primjene DistilBERT-a je detekcija lažnih vijesti, gdje se skoro 90% modela za otkrivanje takvog sadržaja oslanja na ovu tehnologiju. Lažne vijesti predstavljaju ozbiljan problem u suvremenom medijskom prostoru, stvarajući potrebu za pouzdanim i brzim metodama verifikacije informacija. DistilBERT se u ovom kontekstu koristi za analizu i klasifikaciju tekstualnih podataka, identificirajući potencijalno nepouzdane izvore i sadržaje s visokom preciznošću.
Korištenjem DistilBERT-a, moguće je brzo obraditi velike količine informacija, čime se omogućava medijskim organizacijama i tehnološkim platformama da efektivno filtriraju i odbacuju lažne vijesti. Ova primjena ne samo da pomaže u očuvanju integriteta informativnog prostora, nego također štiti korisnike od dezinformacija koje mogu imati široke socijalne i političke posljedice.
DistilBERT nije samo tehnološko dostignuće zbog svoje sposobnosti da djeluje brže i sa manje resursa; njegova prava vrijednost leži u njegovoj primjeni u kritičnim NLP zadacima kao što su klasifikacija i detekcija lažnih vijesti. Kroz svoje visoke performanse i adaptabilnost, DistilBERT pruža ne samo tehnička već i društvena rješenja, čineći digitalni svijet sigurnijim i pouzdanijim mjestom za sve korisnike.
Trening DistilBERT modela
Multilingvalni model DistilBERT predstavlja značajan korak naprijed u pružanju NLP rješenja za različite jezike koristeći jedinstveni model. Ova verzija modela omogućava obradu i razumijevanje teksta na više jezika, što je izuzetno korisno u globaliziranom svijetu gdje se informacije i sadržaji razmjenjuju preko jezičnih i kulturnih granica. Jedna od ključnih prednosti multilingvalnog DistilBERT-a je njegova sposobnost da se efikasno trenira na prilagođenim skupovima podataka, što je urađeno na WELFake datasetu.
Prilikom treniranja multilingvalnog DistilBERT-a na WELFake skupu podataka, istaknute su brojne prednosti ovog pristupa. Korištenjem prijevoda, model je mogao naučiti kako se lažne vijesti manifestiraju rabeći hrvatski jezik, što je omogućilo bolju generalizaciju i preciznost pri detekciji. Osim toga, multilingvalni DistilBERT koristi manje resursa za treniranje u usporedbi s većim modelima, što ga čini idealnim za brzo i efikasno prilagođavanje na specifične skupove podataka poput WELFake.
REZULTATI
| Epoch | Training | Validation | ||
|---|---|---|---|---|
| Average Loss | Average Accuracy | Average Loss | Accuracy | |
| 1 | 0.2168 | 90.07% | 0.1298 | 94.00% |
| 2 | 0.0983 | 96.01% | 0.1237 | 95.10% |
| 3 | 0.0530 | 97.88% | 0.1273 | 95.70% |
| 4 | 0.0277 | 99.08% | 0.1466 | 95.90% |
| 5 | 0.0198 | 99.27% | 0.1773 | 95.10% |
| 6 | 0.0103 | 99.68% | 0.1620 | 95.60% |
| 7 | 0.0173 | 99.37% | 0.1604 | 95.80% |
| 8 | 0.0053 | 99.78% | 0.2753 | 95.30% |
| 9 | 0.0122 | 99.60% | 0.2075 | 95.80% |
| 10 | 0.0028 | 99.88% | 0.2722 | 96.10% |
Gornje navedeni podaci odražavaju performanse strojnog učenja modela tijekom 10 epoha obuke. Svaka epoha predstavlja potpuni prolaz kroz skup podataka za treniranje. Navedene su metrike prosječnog gubitka i točnosti za faze treniranja i validacije.
Metrike Treniranja
- Prosjek Gubitka: Ova metrika mjeri koliko dobro predviđanja modela odgovaraju stvarnim oznakama. Niže vrijednosti gubitka ukazuju na bolje performanse, s predviđanjima modela koja se u većoj mjeri poklapaju s pravim podacima.
- Prosjek Točnosti: Ova metrika pokazuje udio točnih predviđanja koje je model napravio od svih predviđanja. Veća točnost ukazuje na bolje performanse.
Metrike Validacije
- Prosjek Gubitka: Kao i gubitak pri treniranju, ovo mjeri pogrešku predviđanja, ali na zasebnom skupu podataka za validaciju koji se ne koristi za treniranje. Pomaže procijeniti koliko dobro model generalizira na nove, neviđene podatke.
- Točnost: To je točnost modela na skupu podataka za validaciju, slično točnosti treniranja, ali ponovno odražava sposobnost generalizacije.
Promatranja Iz Podataka
- Smanjenje Gubitka i Povećanje Točnosti Tijekom Vremena: Tijekom epoha, gubitak pri treniranju i validaciji općenito se smanjuje, dok točnost raste. To sugerira da model učinkovito uči iz skupa podataka za treniranje i poboljšava svoja predviđanja tijekom vremena.
- Od 1. do 10. Epoha: Primjećuje se značajno poboljšanje od prve do zadnje epohe:
- Gubitak pri treniranju pada s 0.2168 na 0.0028, a točnost treniranja poboljšava se s 90.07% na 99.88%.
- Gubitak validacije na početku pada, zatim raste u kasnijim epohama, što može sugerirati pojavu prenaučenosti; međutim, točnost validacije se općenito poboljšava s 94.00% na 96.10%.
Potencijalna Prenaučenost
Stabilna Točnost Validacije: Unatoč povećanju gubitka validacije, točnost validacije ostaje relativno stabilna i čak se nešto poboljšava. To bi moglo ukazivati na to da model postaje sigurniji u svoja netočna predviđanja (stoga povećani gubitak), ali je i dalje sposoban za točne klasifikacije sličnom ili nešto poboljšanom stopom.
Povećanje Gubitka Validacije u Kasnijim Epohama: Iako gubitak pri treniranju i dalje pada, gubitak validacije počinje rasti nakon što dostigne minimum oko 2. ili 3. epohe. Ova divergencija između gubitka pri treniranju i validaciji tipičan je znak prenaučenosti, gdje model postaje previše prilagođen podacima za treniranje i manje učinkovit u generalizaciji na nove podatke.
Model pokazuje snažne sposobnosti učenja, s izraženim poboljšanjima u gubitku pri treniranju i točnosti.
Točnost validacije, preciznost, odziv i F1 ocjena su ključne metrike koje se koriste za procjenu performansi modela u kontekstu klasifikacijskih zadataka. Evo detaljnije analize svake od ovih metrika i njihovog značenja:
Točnost Validacije (Validation Accuracy)
- Točnost Validacije: 0.9610 – Ova metrika pokazuje udio točno klasificiranih primjera u odnosu na ukupan broj primjera u validacijskom skupu. Vrijednost od 0.9610 znači da model točno predviđa 96.10% slučajeva, što ukazuje na visoku razinu točnosti i generalno dobru sposobnost modela da ispravno identificira i klasificira primjere.
Preciznost (Precision)
- Preciznost: 0.9614 – Preciznost mjeri udio točnih pozitivnih predviđanja u odnosu na ukupan broj pozitivnih predviđanja koje je model napravio. Vrijednost od 0.9614 sugerira da kad model predviđa klasu kao pozitivnu, postoji 96.14% šanse da je to predviđanje točno. Visoka preciznost je posebno važna u aplikacijama gdje su troškovi lažno pozitivnih rezultata visoki.
Odziv (Recall)
- Odziv: 0.9609 – Odziv mjeri udio točnih pozitivnih predviđanja u odnosu na ukupan broj stvarnih pozitivnih primjera u podacima. Vrijednost od 0.9609 znači da model uspješno identificira 96.09% svih stvarnih pozitivnih slučajeva. Ovo je ključno u scenarijima gdje je važno ne propustiti pozitivne slučajeve, kao što su medicinska dijagnostika ili detekcija prevara.
F1 Ocijena (F1 Score)
- F1 Ocijena: 0.9610 – F1 ocijena je harmonijski prosjek preciznosti i odziva. Ova metrika se koristi kada je važno održati ravnotežu između preciznosti i odziva, posebno u situacijama gdje su lažno pozitivni i lažno negativni rezultati podjednako problematični. F1 ocjena od 0.9610 ukazuje na to da model vrlo dobro balansira između ne propuštanja stvarnih pozitivnih slučajeva i ne stvaranja previše lažnih pozitiva.
ROC AUC Ocjena
ROC AUC ocjena je važna metrika u evaluaciji modela strojnog učenja, posebno u kontekstu klasifikacijskih zadataka. jednaka je 0.9609 ROC (Receiver Operating Characteristic) krivulja je graf koji prikazuje performanse klasifikacijskog modela na svim pragovima klasifikacije, dok AUC (Area Under the Curve) predstavlja površinu ispod ROC krivulje. Evo detaljne analize što ROC AUC ocjena od 0.9609 znači:
- ROC AUC Ocijena: 0.9609 – Ova ocjena je izuzetno visoka i ukazuje na to da model vrlo dobro razlikuje između klasa. Vrijednost blizu 1.0 smatra se izvrsnom, dok je vrijednost 0.5 indikacija da model ne radi bolje od nasumičnog pogađanja. Ocijena od 0.9609 sugerira da model ima visoku sposobnost preciznog klasificiranja i pruža pouzdane predikcije.
ROC AUC ocjena je posebno korisna jer ne ovisi o određenom pragu za klasifikaciju. To znači da ocjena pruža općenitu mjeru kvalitete modela bez obzira na to kako su postavljene granice za određivanje pozitivnih i negativnih klasa. To je ključno u aplikacijama gdje nije jasno kako postaviti prag, ili gdje se prag može mijenjati ovisno o specifičnim potrebama korisnika ili regulativnim zahtjevima.
Normalizirana tablica zabune
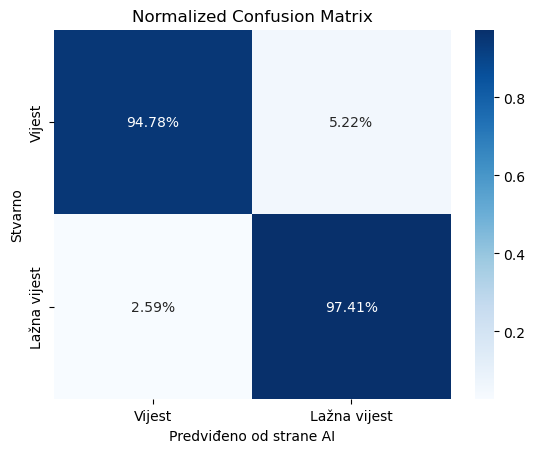
Normalizirana matrica zabune koristan je alat za evaluaciju performansi klasifikacijskih modela, posebno kada se radi o binarnim klasifikacijama kao što su kategorije “Vijest” i “Lažna vijest”. Ova matrica pruža vizualni prikaz točnosti modela u predviđanju svake klase te omogućuje dublje razumijevanje kako model performira na stvarnim podacima u odnosu na predviđanja modela.
U kontekstu naših podataka, normalizirana matrica zabune za dvije klase (“Vijest” i “Lažna vijest”) daje sljedeće vrijednosti:
- Pravi pozitivi (True Positives) za Vijest: 94.78% – Ovo znači da je model točno klasificirao 94.78% stvarnih vijesti kao vijesti.
- Lažni pozitivi (False Positives) za Lažna Vijest: 5.22% – Ovo znači da je model pogrešno klasificirao 5.22% stvarnih vijesti kao lažne vijesti.
- Lažni negativi (False Negatives) za Vijest: 2.59% – Ovo pokazuje da je model pogrešno klasificirao 2.59% stvarnih lažnih vijesti kao vijesti.
- Pravi pozitivi (True Positives) za Lažna Vijest: 97.41% – Ovo znači da je model točno klasificirao 97.41% stvarnih lažnih vijesti kao lažne vijesti.
Analiza Rezultata
- Visoka Točnost za “Lažna Vijest”: Visoka vrijednost pravih pozitiva za lažne vijesti (97.41%) ukazuje na to da model vrlo učinkovito identificira lažne vijesti, što je ključno u kontekstima gdje je važno spriječiti širenje dezinformacija.
- Niža, ali još uvijek visoka Točnost za “Vijest”: Iako je točnost za prave vijesti nešto niža (94.78%), ona je i dalje prilično visoka, što pokazuje da model generalno dobro prepoznaje i vijesti koje su istinite.
- Razmjerno Niski Lažni Pozitivi i Negativi: Iako svaki lažni pozitiv ili negativ predstavlja potencijalni problem, relativno niske vrijednosti za lažne pozitive (5.22%) i lažne negativne (2.59%) pokazuju da model uspješno balansira između prepoznavanja istinitih i lažnih vijesti bez velike količine pogrešaka.
Rezultati pokazuju da model vrlo učinkovito identificira i kategorizira obje klase s visokom točnošću, minimalnim brojem lažnih pozitiva i lažnih negativa.
Ukupno gledano, model pokazuje izvrsne performanse na validacijskom skupu s visokim vrijednostima u svim ključnim metrikama evaluacije. Takva konzistencija u visokim ocjenama točnosti, preciznosti, odziva i F1 ocjene sugerira da je model robustan i dobro generalizira na novim podacima. Ove karakteristike čine ga pouzdanim izborom za praktičnu primjenu, posebno u kritičnim područjima gdje su točnost i pouzdanost od najveće važnosti.